










1. 수업에 적합한 자료
통계는 자료가 많고 복잡할 수록 그 효용성은 커진다.
하지만 그러한 데이터를 항상 얻기는 어렵다. 많은 곳에서 이미 통게적 처리를 한 후의 데이터를 제공하기 때문이다.
원본데이터를 그대로 제공하는 일은 드물다.
가공된 데이터를 다루는 것은 학생들에게 중요한 사고과정을 뺏는 일일 수 있다.
학습하는 과정이니 가공된 데이터를 통해 임의로 원본데이터를 만들어 학습자료로 활용할 수 있지만
데이터의 크기가 큰 경우 이를 직접 만드는 것은 쉬운일이 아니다.
이에 chatgpt를 이용해서 자료를 처리해보았다.
2. gpt를 활용한 자료처리
https://its.sc.go.kr/stat/traffic.view 의교통량 데이터를 소재로 사용해보려고한다.
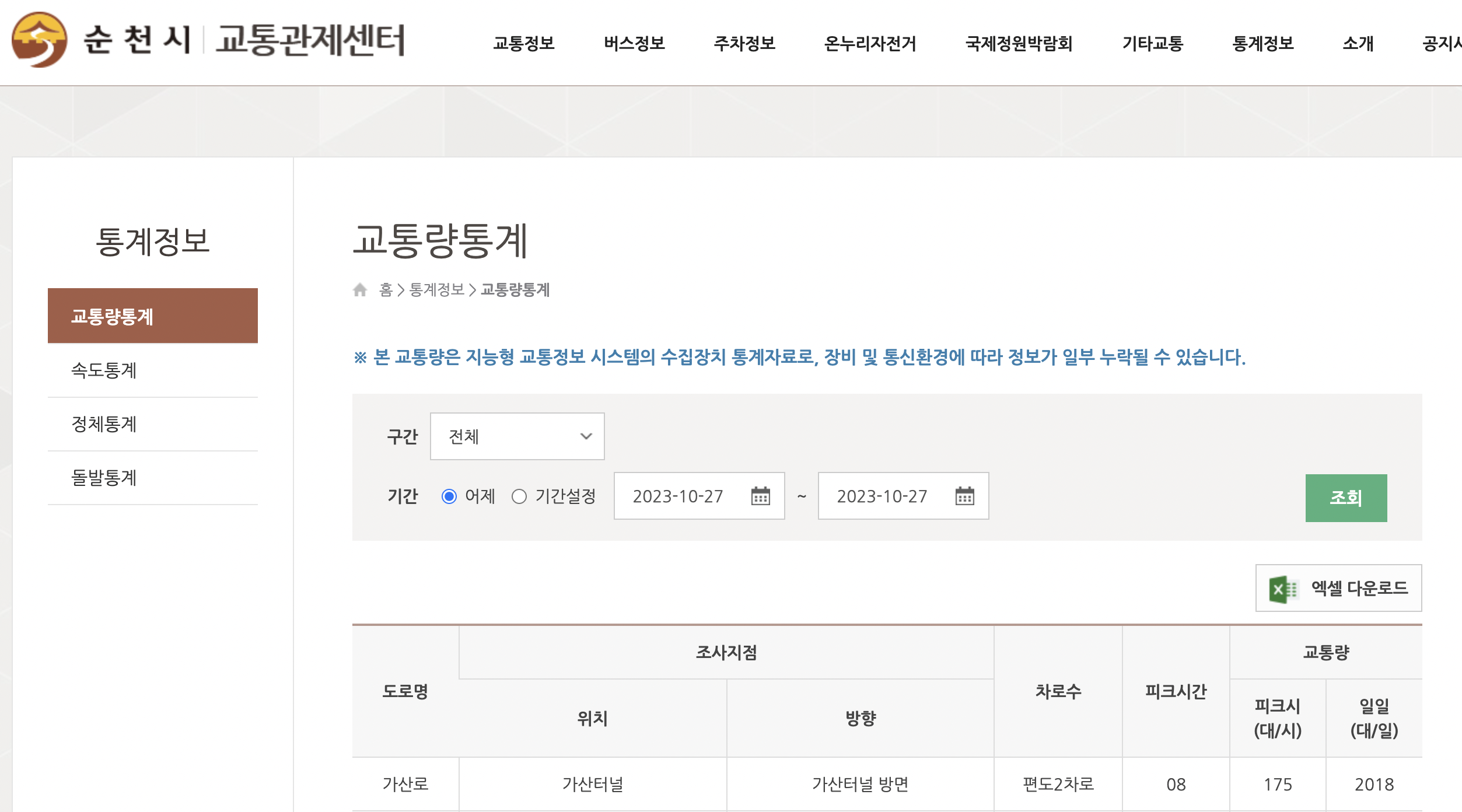
위처럼 실제 각 데이터의 시간정보는 제공하지 않고 피크시간과 일일 교통량만 제시하는 형태이다.
피크시간을 구하거나 시간대별 차량 통행량의 정보등은 이미 원자료를 가공한 상태로 볼 수 있다.
따라서 이러한 자료형태일 때, chatgpt를 통해 원본자료를 가상으로 만들어달라고 요청해볼 생각이다.
2-1. chatgpt 요청하기
총 2018개의 시간데이터를 받아와야 한다. 이 것은 기본 chatgpt가 하기 어려운 작업이다.
llm모델의 구조상 어려움과 만약 가능하더라도 사용 토큰수를 넘어갈 수 있기 때문이다.
이를 위해 적절히 코드를 만들고 코드를 실행하여 파일로 저장하게 해야한다.
gpt 유료모델을 쓰면 쉽게 가능하다.
advanced data annalysis를 선택하자. 이는 파이썬 코드를 작성하며 데이터를 처리해주기 때문에 우리가 하고자 하는 일이 가능하다. 그렇지 않을 경우에는 프롬프트를 코드 작성방법을 묻고 이를 colab등에서 실행하여 원하는 결과를 얻어야 할 것이다.
https://chat.openai.com/share/0f8f28a7-8b78-424e-9d72-99da2f1acb65
대화내용은 위와 같다. 시작은 다음과 같이 물어보았다. 내가 찾은 자료의 내용을 바탕으로 먼저 시간대별로 알려달라고 한후
한 도로의 교통량 피크시간은 오전8시-9시이고 그 때 통행량은 175대야. 일일 총 통행량은 2018대라고 할 때, 각 시간대별로 통행량을 예상해서 적절히 분포시켜줘. 24시간대별로 통행량을 제시하고 실제 데이터처럼 적절히 분산되어 있어야 해.
마지막에는 엑셀파일로 각 시간대별로 랜덤하게 시간을 배치해달라고도 요청하였다.
그렇게 해서 얻은 엑셀파일을 첨부파일로 첨부한다.
파일은 2018개의 시간데이터가 있으며 내가 처음 접한 통계적으로 가공된 데이터에 해당하는 가상의 원본자료를 생성한 것이다.




























[삭제된 사용자의 댓글입니다]
메모를 입력하세요